How can you make your data more discoverable?
Description
Data discovery involves processes and tools that help users understand what data is available, where it is stored, and how to access it. It includes querying datasets to find specific information based on given conditions. However, for data to be discoverable, it must be well-prepared. Making your data discoverable maximises its impact and utility, enabling others to find, access, and use it effectively. Discoverable data promotes transparency, reproducibility, and scientific progress. Achieving this requires detailed metadata and documentation, depositing data in public and institutional repositories, and using standardised formats for interoperability.
Considerations
- Detailed Metadata: Provide comprehensive metadata for your datasets, including titles, descriptions, keywords, creators, dates, and other relevant information.
- Documentation: Include thorough documentation that explains the dataset, its structure, how it was collected and processed, and any limitations.
- Standard Schemas: Use standardised metadata schemas to ensure consistency and interoperability.
- Standard Formats: Use widely accepted data formats to ensure compatibility and ease of use.
- Public Repositories: Deposit your data in reputable public data repositories that are indexed by search engines and widely used by the research community.
Solutions
- There are several appropriate tools to create detailed (or comprehensive) metadata and document data properly for the project. Check the Documentation and metadata page for more information.
- Some scientific communities utilise platforms such as CEDAR, Semares, FAIRDOM-SEEK, FAIRDOMHub, and COPO for managing metadata and data.
- Various standards exist for different data types, from general dataset descriptions such as Data Catalog Vocabulary (DCAT), Dublin Core Metadata Terms, Schema.org and Bioschemas, to those tailored for specific data types, such as MIABIS for biosamples. Hence, selecting the appropriate standard at the project’s outset is crucial. Typically, if you choose a suitable data repository for your data, it will come with an integrated metadata scheme, simplifying your work by eliminating the need to develop a separate metadata profile.
- Decide at the beginning of the project the right repository for your data type. To search for it, you can use the ELIXIR Deposition Databases for Biomolecular Data, re3data or FAIRsharing at “Databases”.
- If your chosen repository lacks some of the metadata fields you wish to include and you need to add a separate file with this information (such as in Zenodo), you should adhere to the appropriate metadata schema. To identify the correct schema, you have several options:
- RDA Standards
- FAIRsharing at “Standards” and “Collections”
- Data Curation Centre Metadata list
- The ideal file formats vary based on the type of data, the availability and common acceptance of open file formats, and the research domain. There isn’t a universal solution, so selecting the most suitable format for your specific needs is essential. The Data Organisation page provides a table with recommended file formats and best practices for research data management.
How can you discover controlled access data?
Description
Discovering research data for re-analysis can occur at different levels of granularity. Initially, researchers browse online catalogues that describe studies, datasets, related publications, variables, and some data distributions. This basic discovery may suffice if the datasets meet all the criteria. However, to find dataset that meet specific combinations of attributes — such as identifying datasets with particular combinations of attributes, like ‘adults diagnosed with COVID-19 in the last year, fully vaccinated, with no underlying health conditions’ (for example) — researchers must either contact the authors or request data access and verify themselves. This process is feasible for a small number of datasets and cooperative data controllers but it is usually time-consuming and uncertain. To streamline this, data discovery at the source allows users to query data non-disclosively, determining its relevance before requesting full access.
Considerations
- Detailed Metadata: ensure comprehensive metadata for your datasets, including detailed descriptions of studies, datasets, variables, and any available distributions.
- Data Catalogues and Repositories: use well-maintained online catalogues and repositories that support controlled access data, and check for advanced search features to filter datasets by specific attributes.
- Data Access Policies: get familiar with the data access policies of different repositories and datasets, understanding the requirements and procedures for requesting access to controlled data.
- Ethical and Legal Compliance: ensure compliance with ethical guidelines and legal regulations governing data use and sharing, and obtain necessary approvals from institutional review boards or ethics committees if required. Check the GDPR compliance and Ethical aspects pages for more information.
- Data Access Request Process: be aware that the process for requesting and obtaining data access can be time-consuming, and prepare detailed justifications for data access requests, including research objectives and intended analyses.
- Privacy and Security Measures: implement robust privacy and security measures to protect sensitive data during discovery and after access is granted, ensuring data handling practices comply with data protection regulations. Check the Data sensitivity page for more information.
Solutions
Beacon, developed through the Global Alliance for Genomics and Health (GA4GH) Discovery workstream, and with substantial support from ELIXIR, serves as a data discovery protocol and specification defining an open standard for discovering genomic and phenoclinic data in biomedical research and clinical applications.
The latest version, Beacon v2, introduced expanded query options, enabling the retrieval of biological or technical (meta)data through filters defined via CURIEs. This includes, but not limited to, parameters such as phenotypes, disease codes, sex, or age, providing researchers with a nuanced approach to data inquiries.
Beacon v2 is organised in two main blocks: the Beacon Framework and the Beacon Model. The Framework defines the format for the requests and responses, whereas the Model defines the structure of the biological data response.
This dual-system approach not only broadens the scope for diverse Models – using different domains such as images, pathogens, or infectious diseases – but also reinforces the adaptability of the Framework. The overall function of these components is to provide the instructions to design a REST API that could be implemented as a stand-alone product or, preferably, extending existing data management solutions.
Consequently, the ‘beaconised’ data represents a significant enhancement in data discoverability with minimal risks. Currently, there are two ways to implement a Beacon:
-
API on top of existing tools: This APIs is targeted to those organisations equipped with well-organised and structured data housed in databases, whether SQL or NoSQL, and possess the necessary resources and expertise to interpret and implement the Beacon v2 specification and construct an API on top of an existing tool.
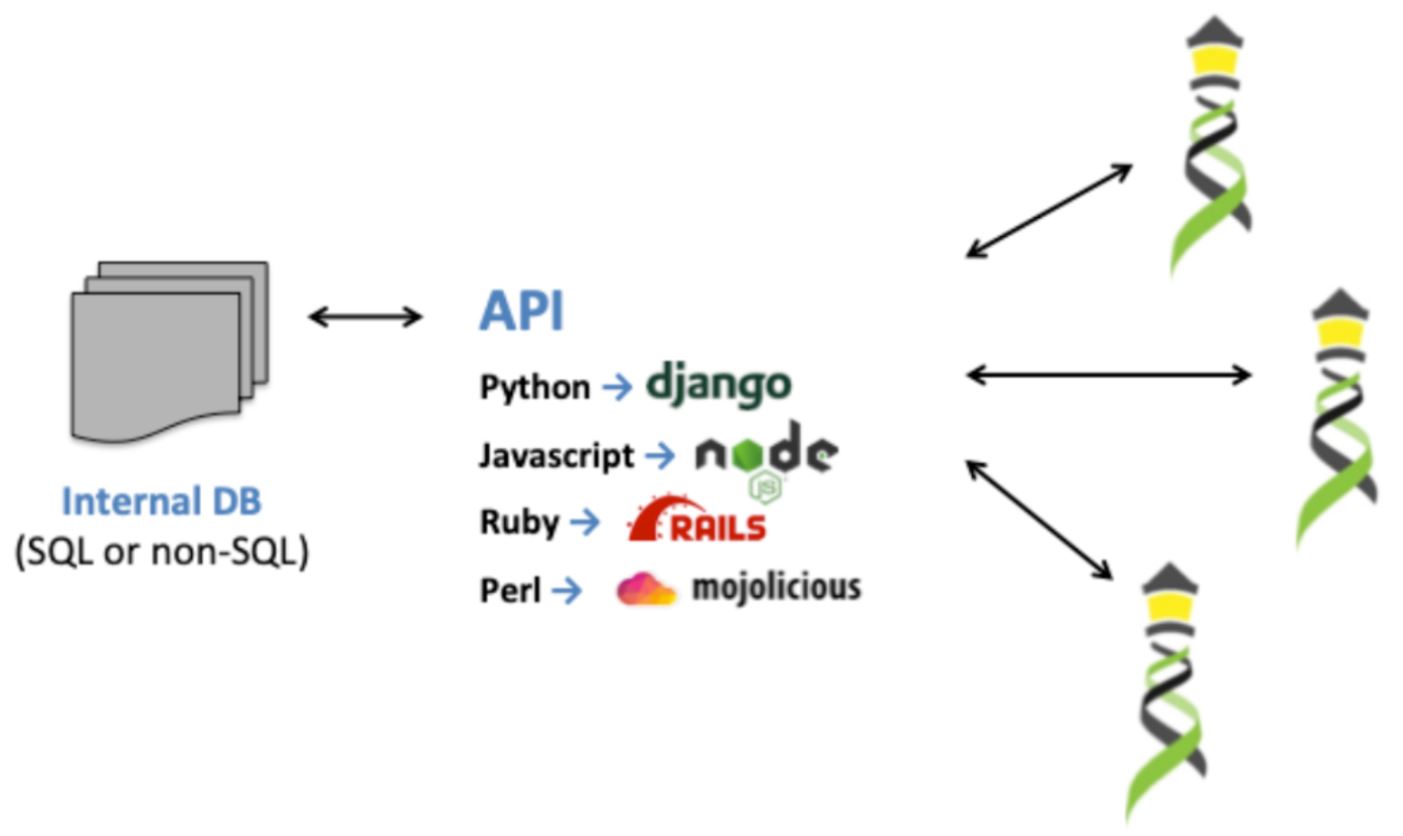
Figure 1. Beacon API functionality (Source)
-
Beacon v2 Reference Implementation (B2RI): an out-of-the-box example implementation of the Beacon v2 protocol. It is an open-source toolkit based on Python programming language and consists of tools for loading metadata, e.g. phenotypic data, from a CSV file and genomic variants from a VCF file into a MongoDB database. It also features the Beacon query engine (REST API) and comes bundled with an example dataset (CINECA synthetic cohort EUROPE UK1) comprising synthetic data. You can find the GitHub Repository for Beacon v2 here.
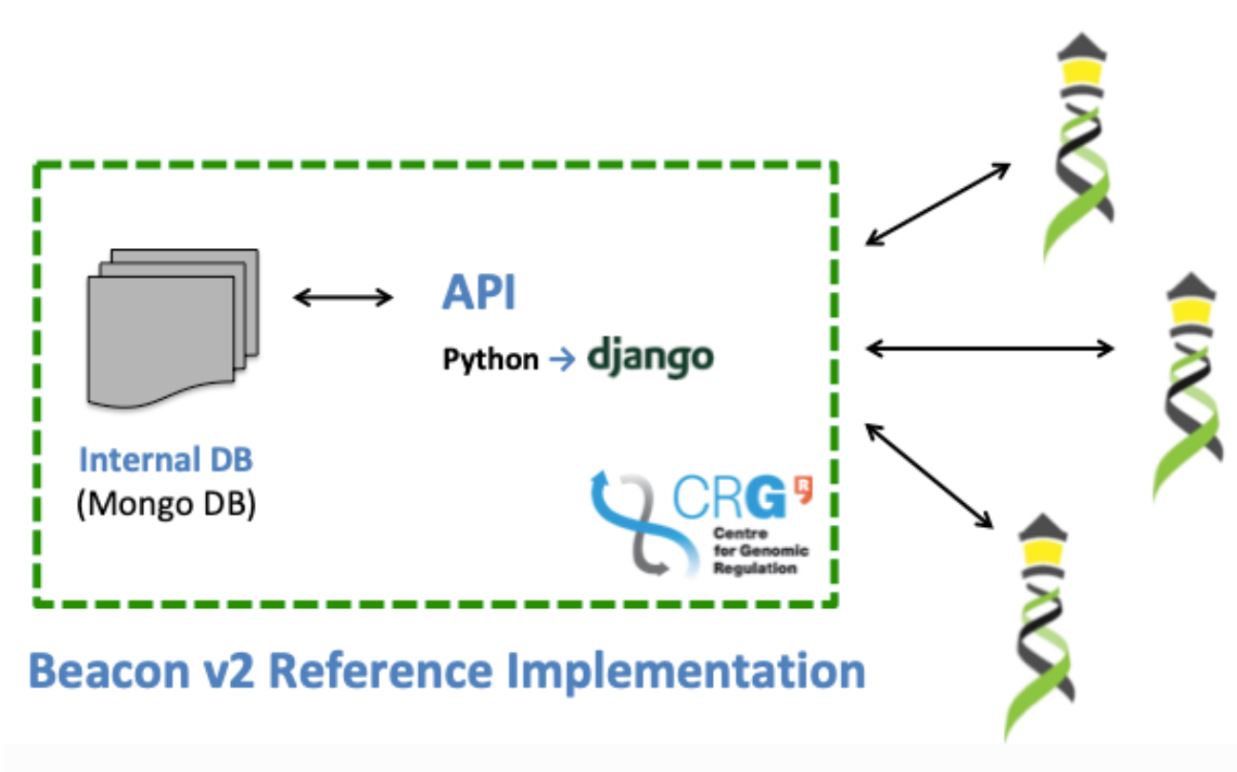
Figure 2. Beacon RI functionality. (Source)
Building on B2RI, the Beacon for OMOP (B4OMOP) software allows for the integration of a Beacon onto any OMOP Common Data Model (CDM) database. This enables organisations using the OMOP CDM to leverage the Beacon framework for querying and sharing genomic and phenotypic data.
More information
Links to FAIR Cookbook
FAIR Cookbook is an online, open and live resource for the Life Sciences with recipes that help you to make and keep data Findable, Accessible, Interoperable and Reusable; in one word FAIR.
Tools and resources on this page
| Tool or resource | Description | Related pages | Registry |
|---|---|---|---|
| Beacon | The Beacon protocol defines an open standard for genomics data discovery. | Human data | Tool info Standards/Databases Training |
| Beacon for OMOP (B4OMOP) | Beacon for OMOP (B4OMOP) software allows for the integration of a Beacon onto any OMOP Common Data Model (CDM) database. | ||
| Beacon v2 | Developed through the Global Alliance for Genomics and Health (GA4GH) Discovery workstream with support from ELIXIR, Beacon is a data discovery protocol defining an open standard for discovering genomic and phenoclinic data in research and clinical applications. | Training | |
| Beacon v2 Reference Implementation (B2RI) | An open-source out-of-the-box toolkit to initiate a Beacon v2. B2RI includes tools for loading metadata, such as phenotypic data and genomic variants into a MongoDB database, and features a Beacon query engine (REST API). | ||
| Bioschemas | Bioschemas aims to improve the Findability on the Web of life sciences resources such as datasets, software, and training materials | Plant Phenomics Agroecology Enzymology and biocata... Intrinsically disorder... Virology Machine actionability Documentation and meta... | Tool info Standards/Databases Training |
| CEDAR | CEDAR is making data submission smarter and faster, so that scientific researchers and analysts can create and use better metadata. | Documentation and meta... | Tool info Standards/Databases |
| COPO | Collaborative OPen Omics (COPO) is a portal for scientists to describe, store and retrieve data more easily, using community standards and public repositories that enable the open sharing of results. The COPO project is one of several projects supported by the [Earlham Institute](https://www.earlham.ac.uk/research-project/collaborative-open-omics-copo) (EI), in Norwich, United Kingdom. | Plant Phenomics Biodiversity Plant sciences Documentation and meta... | Tool info Standards/Databases |
| Data Catalog Vocabulary (DCAT) | DCAT is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web. | Rare disease data Virology Machine actionability Documentation and meta... | Standards/Databases |
| Data Curation Centre Metadata list | List of metadata standards | Documentation and meta... | |
| Dublin Core Metadata Terms | A metadata standard for describing resources of any kind. | Virology Data provenance Machine actionability Documentation and meta... | Standards/Databases |
| ELIXIR Deposition Databases for Biomolecular Data | List of discipline-specific deposition databases recommended by ELIXIR. | CSC IFB Marine Metagenomics NeLS Data interlinking Data publication Existing data Documentation and meta... | Standards/Databases Training |
| FAIRDOM-SEEK | A data Management Platform for organising, sharing and publishing research datasets, models, protocols, samples, publications and other research outcomes. | NeLS Plant Phenomics Microbial biotechnology Plant sciences Documentation and meta... Data storage | Tool info |
| FAIRDOMHub | Data, model and SOPs management for projects, from preliminary data to publication, support for running SBML models, etc. (public SEEK instance) | NeLS Plant Genomics Plant Phenomics Microbial biotechnology Plant sciences Documentation and meta... | Standards/Databases Training |
| FAIRsharing | A curated, informative and educational resource on data and metadata standards, inter-related to databases and data policies. | FAIRtracks Health data Microbial biotechnology Plant sciences Virology Data provenance Data publication Existing data Machine actionability Documentation and meta... | Standards/Databases Training |
| MIABIS | Minimum Information About Biobank data Sharing (MIABIS) is dedicated to standardising data elements used to describe biobanks, research on samples, and associated data. | Documentation and meta... | Standards/Databases |
| RDA Standards | Directory of standard metadata, divided into different research areas | Data provenance Documentation and meta... | |
| re3data | Registry of Research Data Repositories | Data publication Existing data Licensing | Training |
| Schema.org | Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond. | Agroecology Enzymology and biocata... Machine learning Machine actionability Documentation and meta... | Tool info Standards/Databases Training |
| Semares | All-in-one platform for life science data management, semantic data integration, data analysis and visualisation | Documentation and meta... Data storage |

Aina Jené Cortada
European Genome-phenome Archive (EGA) / CRG

Laura Portell Silva
Barcelona Supercomputing Center / ELIXIR-ES

Bert Droesbeke
VIB Data Core / ELIXIR-BE
Laura Portell Silva
Barcelona Supercomputing Center / ELIXIR-ES

Nazeefa Fatima
Centre for Bioinformatics, University of Oslo / ELIXIR-NO